We all know, in recent years, javascript has become a highly developed programming language. Many developers are getting interested in using javascript, and it’s becoming the most popular language in the world.
Currently, you can see how many libraries and frameworks are built using javascript. It is a very easy language to learn, works well when combined with other languages and can be used in a variety of applications. And now, we also know how Node.js became a trend in backend programming. In fact, this is the main reason why some big companies with heavy traffic use Node.js on their platforms like eBay, Microsoft, Yahoo, Netflix and LinkedIn.
Node.js is known event-driven I/O server-side JavaScript environment and single-threaded event loop based on V8 Engine ( Google’s open source high-performance JavaScript engine). The event-driven architecture of node.js is very good technology for real-time applications, especially chat applications and streaming applications. As both the client-side and the server-side are written in JavaScript, the synchronization process which design by single-threaded is better and quicker.
With good productivity on Node.js, practically you also want how Node.js can be more optimal. In this article will discuss 6 ways to make node js to be faster and optimal in work.
1. Caching Your App with Redis

What is caching?On caching process, Redis as a more complex version of Memcached. Redis always served and modified data in the server’s main memory. The impact is system will quickly retrieve data that will be needed. It also reduces time to open web pages and make your site faster. Redis works to help and improve load performance from relational databases or NoSQL by creating an excellent in-memory cache to reduce access latency. Using Redis we can store cache using SET and GET, besides that redis also can work with complex type data like Lists, Sets, ordered data structures, and so forth.
We will make a comparison of 2 pieces of code from Node.js. The following is when we try to retrieve data from the Google Book API, without put Redis on the endpoint.
Node.Js without Redis :
'use strict';
//Define all dependencies needed
const express = require('express');
const responseTime = require('response-time')
const axios = require('axios');
//Load Express Framework
var app = express();
//Create a middleware that adds a X-Response-Time header to responses.
app.use(responseTime());
const getBook = (req, res) => {
let isbn = req.query.isbn;
let url =https://www.googleapis.com/books/v1/volumes?q=isbn:${isbn};
axios.get(url)
.then(response => {
let book = response.data.items
res.send(book);
})
.catch(err => {
res.send('The book you are looking for is not found !!!');
});
};
app.get('/book', getBook);
app.listen(3000, function() {
console.log('Your node is running on port 3000 !!!')
});
And now, we will put a redis on this endpoint.
Node.Js with Redis :
'use strict';
//Define all dependencies needed
const express = require('express');
const responseTime = require('response-time')
const axios = require('axios');
const redis = require('redis');
const client = redis.createClient();
//Load Express Framework
var app = express();
//Create a middleware that adds a X-Response-Time header to responses.
app.use(responseTime());
const getBook = (req, res) => {
let isbn = req.query.isbn;
let url =https://www.googleapis.com/books/v1/volumes?q=isbn:${isbn};
return axios.get(url)
.then(response => {
let book = response.data.items;
// Set the string-key:isbn in our cache. With he contents of the cache : title
// Set cache expiration to 1 hour (60 minutes)
client.setex(isbn, 3600, JSON.stringify(book));
res.send(book); }) .catch(err => { res.send('The book you are looking for is not found !!!'); });
};
const getCache = (req, res) => {
let isbn = req.query.isbn;
//Check the cache data from the server redis
client.get(isbn, (err, result) => {
if (result) {
res.send(result);
} else {
getBook(req, res);
}
});
}
app.get('/book', getCache);
app.listen(3000, function() {
console.log('Your node is running on port 3000 !!!')
});
You can see, the above code explains that redis will store the cache data of with unique key value that we have specified, using this function:
client.setex (isbn, 3600, JSON.stringify(book));
And take the cache data using the function below:
client.get(isbn, (err, result) => {
if (result) {
res.send (result);
} else {
getBook (req, res);
}
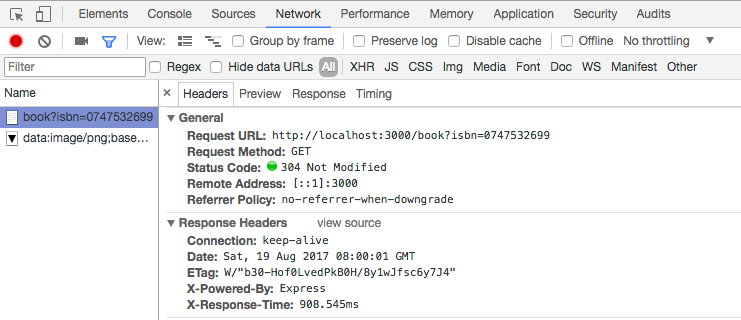
});This is the result of testing of both codes. If we don’t use redis as cache, it takes at least 908.545 ms
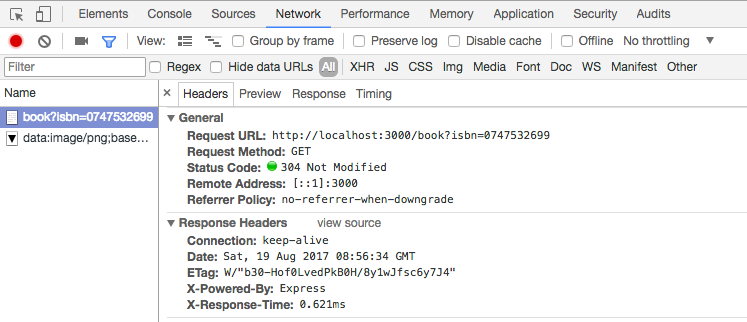
Very different, when node js use redis. Look at this, it is very fast, it only takes 0.621 ms to retrieve data at the same endpoint
2. Make sure your query is Optimized
Basically, the process generated by database in the query greatly affects performance. When end-point generates data that called by the system. A bad query, will make the process of displaying data becomes very slow. For example, if we have a data on MongoDB, the problem is when we have 4 million rows of data, to find 1 desired data keyword, without using index schema that will be make query process very slow. With MongoDB, we can analyze how a query process can work. You can add this query : explain(“executionStats”) to analyze and find user data from your collection.
> db.user.find({email: 'ofan@skyshi.com'}).explain("executionStats")Look at this, before we create the index, response query when looking for data.
> db.user.find({email: 'ofan@skyshi.com'}).explain("executionStats")
{
"queryPlanner" : ...
},
"winningPlan" : {
"stage" : "COLLSCAN",
"filter" : {
"email" : {
"$eq" : "ofan@skyshi.com"
}
},
"direction" : "forward"
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 1,
"executionTimeMillis" : 0,
"totalKeysExamined" : 0,
"totalDocsExamined" : 1039,
"executionStages" : {
...
},
...
}
},
"serverInfo" : {
...
},
"ok" : 1
}
>From the above JSON results, there are 2 important points that we can analyze that is :
nReturned :displays 1 to indicate that the query matches and returns 1 documents.totalDocsExamined :MongoDB has scanned 1039 document data (this searches on all documents), to get 1 desired data.
This is when we try to add index email to the user collection.
> db.getCollection("user").createIndex({ "email": 1 }, { "name": "email_1", "unique": true })
{
"createdCollectionAutomatically" : false,
"numIndexesBefore" : 1,
"numIndexesAfter" : 2,
"ok" : 1
}The result of query analysis after add index email
> db.user.find({email: 'ofan@skyshi.com'}).explain("executionStats")
{
"queryPlanner" : ...,
"winningPlan" : {
"stage" : "FETCH",
"inputStage" : {
"stage" : "IXSCAN",
"keyPattern" : {
"email" : 1
},
"indexName" : "email_1",
"isMultiKey" : false,
"isUnique" : true,
...
}
},
"rejectedPlans" : [ ]
},
"executionStats" : {
"executionSuccess" : true,
"nReturned" : 1,
"executionTimeMillis" : 0,
"totalKeysExamined" : 1,
"totalDocsExamined" : 1,
...
}
}
},
"serverInfo" : {
...
}You can see, at the totalDocsExamined point, MongoDB only searches for 1 related data, this will make query process more faster and more efficient. Here’s the advantage when you add the index to MongoDB. By adding an index, it will also be useful when you want to sort data in a collection.
3. Check All Error Scripts with Logging
Why is logging important? The first is that you must ensure that your application program is running properly, without any fatal errors. If at any time, you find something strange in your program, it is time to find out what code makes the error. With logging, you can track activity and API process traffic.
The logging process that people often use is to use console.log (‘Log Ouput’) by default it will insert some logs on the output standard (stdout) and console.error (‘Log Error’) also will go in error standard (stderr). However, I recommend that you use a more popular and efficient logging module, such as Winston, Morgan and Buyan.
I will give an example of how we are logging using winston . In general, winston has 4 custom levels that we can use such as: error, warn, info, verbose, debug, and silly.
Some features that can be used on winston:
- Possible to use multiple transports of the same type
- Simple Profiling
- Supports querying of logs
- Possible to catch and log uncaughtException
- Setting the level for your logging message
First of all we need to install Winston and include winston on the new project or that you have developed. Run the following command to do this:
npm install winston --save
This is the basic configuration wintons that we use :
const winston = require('winston');
let logger = new winston.Logger({
transports: [
new winston.transports.File({
level: 'verbose',
timestamp: new Date(),
filename: 'filelog-verbose.log',
json: false,
}),
new winston.transports.File({
level: 'error',
timestamp: new Date(),
filename: 'filelog-error.log',
json: false,
})
]
});
logger.stream = {
write: function(message, encoding) {
logger.info(message);
}
};From the code above we know that, we do use multiple transports configuration, with 2 levels logging that are verbose and error.
4. Implement HTTP/2

HTTP/2 commonly called SPDY is the latest web protocol standard developed by the IETF HTTP workgroup. HTTP/2 makes web browsing faster, easier and lower bandwidth usage. It focuses on performance, especially to solve problems that still occur in previous versions of HTTP/1.x. Currently, you can see some popular web like google, facebook and youtube, have implemented the HTTP/2 protocol on its web page.
Why is this better than HTTP/1.x?
- Multiplexing:
Multiplexing will allow multiple requests and response messages to retrieve resources in a single TCP connection simultaneously. - Header Compression :
Each request via HTTP contains header information. With HTTP/1.1, many headers are repeated in one session and duplicate the same info. This overhead is considerable, HTTP/2 removes the excess header while pressing the remaining headers and forcing all HTTP headers to be sent in a compressed format. - Server Push:
With HTTP/1.1 it must wait for the client to send the connection. Server Push allows the server to avoid delays in sending data by “pushing” responses that it claims the client needs to cache it and automatically this will speed up page load time by reducing the number of requests. - Binary Format :
HTTP / 1.1 sends data in the textual format, while HTTP/2 sends data in binary format. Binary protocols are more efficient to parse and reduce the number of errors, compared to previous versions of textual protocols.
And we know, Node.js currently supports and provides HTTP/2 implementations for core Node.js. The API is very similar to the standard node.js HTTPS API. To start with HTTP/2, you can create an HTTP/2 server on Node.js using the following code line:
const http2 = require('http2');
const fs = require('fs');
const hostname = '127.0.0.1';
const port = 3000;
const options = {
key: fs.readFileSync('server.key'),
cert: fs.readFileSync('server.crt'),
requestCert: false,
rejectUnauthorized: false
};
// Create a plain-text HTTP/2 server
const server = http2.createSecureServer(options);
server.on('stream', (stream, headers) => {
stream.respond({
'content-type': 'text/html',
':status': 200
});
stream.end('Hello Word');
});
server.listen(port, hostname, () => {
console.log(Server running at https://${hostname}:${port}/ !!!);
});To implement Transport Layer Security (TLS) and Secure Socket Layer (SSL) protocols that built on OpenSSL.
Because HTTP/2 support is still experimental, Node.js must be launched with the --expose-http2 command line :
$ node --expose-http2 node-http2.js
Now it’s time to check if a website is using the newest HTTP/2 protocol.
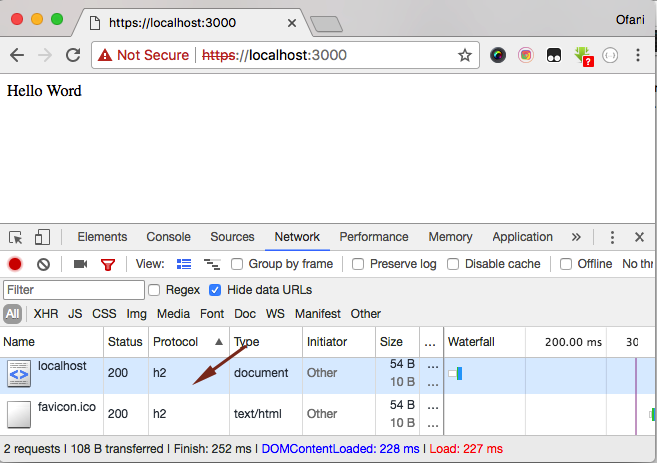
From the picture above, you will be able to identify that the website has been using the HTTP/2 protocol.
5. Clustering Your Node .js
By default, Node.js runs on a single thread on a single-core of the processor. and It does not utilize several cores that may be available in a system. But now, with cluster on Node.js, it allows you to easily create child processes that all share server ports. it’s meant that cluster can handle a large volume of requests with multi-core systems. And automatically, this will increase the performance of your server.
Node.js Cluster Module
Node.js has implementation the core cluster modules, that allowing applications to run on more than one core. Cluster module a parent/masterprocess can be forked in any number of child/worker processes and communicate with them sending messages via IPC communication. Let’s see a small code snippet below :
const cluster = require('cluster');
const http = require('http');
const numCPUs = require('os').cpus().length;
const express = require('express');
var app = express();
if (cluster.isMaster) {
console.log(Master ${process.pid} is running);
// Fork workers.
for (let i = 0; i < numCPUs; i++) {
cluster.fork();
}
//Check if work id is died
cluster.on('exit', (worker, code, signal) => {
console.log(worker ${worker.process.pid} died);
});
} else {
// This is Workers can share any TCP connection
// It will be initialized using express
console.log(Worker ${process.pid} started);
app.get('/cluster', (req, res) => {
let worker = cluster.worker.id;
res.send(Running on worker with id ==> ${worker});
});
app.listen(3000, function() {
console.log('Your node is running on port 3000');
});
}When the node is run, there it appears that there are 4 workers currently in use on Node.js with a cluster.
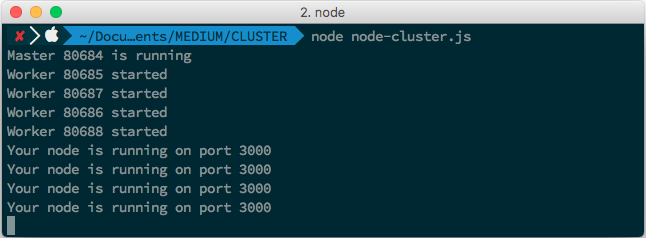
Now you can visit the http:localhost:3000/cluster link on a different tab and browser, you will find there, that each tab will have a different worker id.
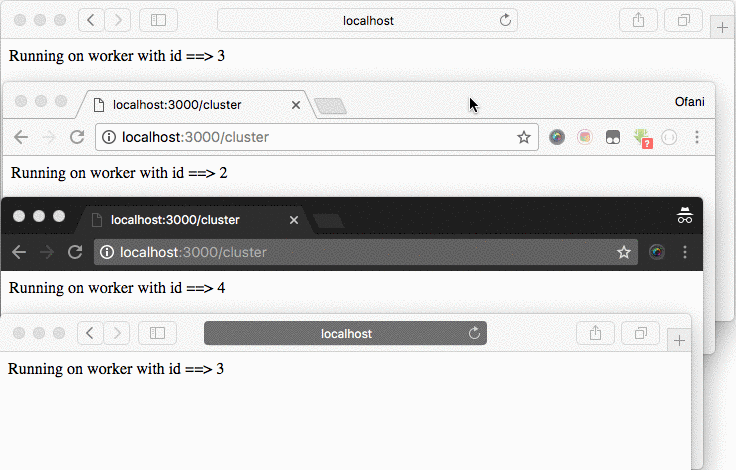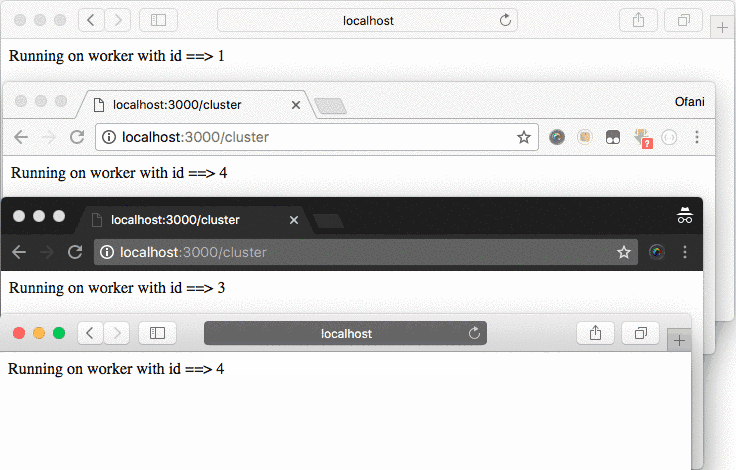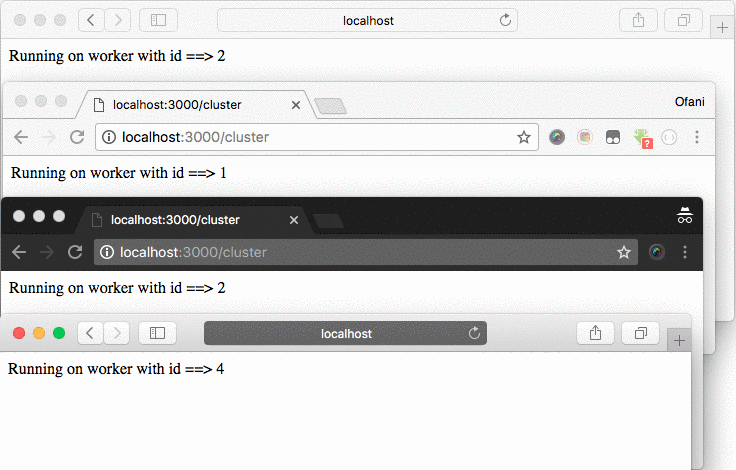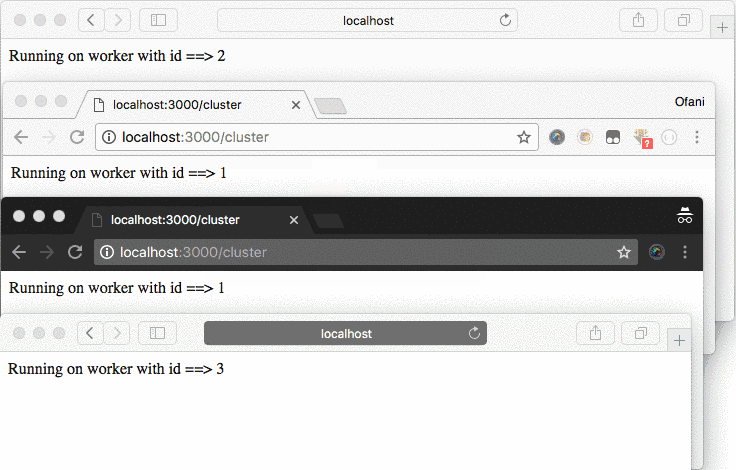
Node.js clustering with PM2
PM2 is a production process manager for Node.js applications with a built-in load balancer. It allows you to keep applications alive forever, to reload them without downtime and to facilitate common system admin tasks. One of its nicer features is an automatic use of Node’s Cluster API. PM2 gives your application the ability to be run as multiple processes, without any code modifications. For example, below is a simple code built using express :
'use strict';
//Define all dependencies needed
const express = require('express');
const responseTime = require('response-time')
const axios = require('axios');
//Load Express Framework
var app = express();
app.get('/cluster', (req, res) => {
res.send('Hello Word');
});
app.listen(3000, function() {
console.log('Your node is running on port 3000 !!!')
});
With command below, PM2 will automatically spawn as many workers as you have CPU cores. Let’s start and following commands to enable cluster using PM2:
pm2 start app.js -i 0Now you can see, how PM2 cluster has scaled accross all CPUs available
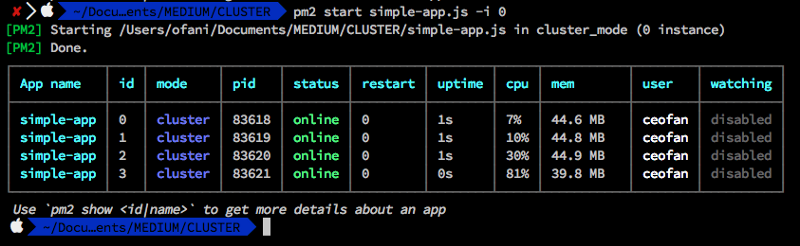
Overall, PM2 cluster is powerful tools that can really improve the concurrency and overall performance of your Node JS. This is easier than you are using an existing cluster module on Node.js Core.
6. Use Realtime App Monitor to Analysis your App
Real Time Monitoring is a third-party application that allows admins to maintain and monitor the system from any disruptions or problems that arise in web applications in real time. This lets you immediately respond to any errors or bugs that occur. In Node JS you can use Newrelic, Stackify, Ruxit, LogicMonitor and Monitis, to record traces and activities quickly, concisely and reliably. With this monitoring, you can analyze and find out more detail issues, especially the effectiveness and health of node.js when accessed by multiple users.
Conclusion :
I know there are still many ways to improve and speed up performance on Node.js, and with only 6 ways above, I think not enough to make your Node.js run perfectly.